
[Spring Data JPA] 2-4. @EntityGraph, JPA Hint & Lock
@EntityGraph
Fetch Join
아래 코드의 상황은 member1이 teamA를 참조하고, member2가 teamB를 참조하고 있으며, Member와 Team의 관계는 @ManyToOne 지연로딩 관계이다.
@Test
public void findMemberLazy() {
// given
// member1 -> teamA
// member2 -> teamB
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
teamRepository.save(teamA);
teamRepository.save(teamB);
Member member1 = new Member("member1", 10, teamA);
Member member2 = new Member("member2", 10, teamB);
memberRepository.save(member1);
memberRepository.save(member2);
em.flush();
em.clear();
// when -> N + 1
// select Member 1
List<Member> members = memberRepository.findAll(); // 쿼리 수 : 1개
for (Member member : members) {
System.out.println("member = " + member);
System.out.println("member.teamClass = " + member.getTeam().getClass()); // team 프록시 객체 확인: class study.data_jpa.entity.Team$HibernateProxy$AMEiLaSy
// team 객체 프록시 초기화
System.out.println("member.team = " + member.getTeam().getName()); // 쿼리 수 : member 수만큼
}
}N + 1 문제 발생
모든 Member를 가져오기 위한 쿼리(1개. Team은 프록시 객체) + 각 Member의 Team이 모두 다른 경우, Member 1명 당 Team 프록시 객체 초기화를 하기 위한 쿼리(N개)
Fetch Join으로 문제 해결
Fetch Join을 사용하면 Member와 연관된 Team을 모두 Select 절에서 조회해 한방 쿼리로 가져온다.
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin();
실행된 결과를 보면, select 절에 Member 필드의 값 뿐만 아니라 Team의 필드 값까지 조회해오는 것을 볼 수 있다. 이는 한방 쿼리로 모든 객체를 다 가져오기 때문에 Member 엔티티의 Team 객체에 실제 Team 객체를 생성해서 넣어준다.
@EntityGraph
Spring Data JPA는 JPA가 제공하는 @EntityGraph를 사용해서 JPQL 없이 페치 조인을 사용할 수 있다.(JPQL + @EntityGraph도 가능)
@EntityGraph(attributePaths = {"fetch join할 객체의 필드명"} 형식으로 추가해서 사용할 수 있다.
// @EntityGraph
@Override
@EntityGraph(attributePaths = {"team"}) // JPQL 없이도 객체 그래프를 한 번에 엮어서 성능 최적화를 해서 가지고 온다.
List<Member> findAll();
// JPQL + @EntityGraph(fetch join)
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph(); // @EntityGraph와 JPQL을 같이 사용 가능
// 메서드 이름으로 쿼리 생성 + @EntityGraph(fetch join)
@EntityGraph(attributePaths = {"team"})
List<Member> findEntityGraphByUsername(@Param("username") String username);즉, Entity Graph는 사실상 페치 조인의 간편 버전으로 LEFT OUTER JOIN을 사용하는 것이다.
참고! @NamedEntityGraph + @EntityGraph (거의 사용 안함)
@NamedEntityGraph(name = "Member.all", attributeNodes = @NamedAttributeNode("team"))
public class Member {...}Member 엔티티 위에 @NamedEntityGraph(name = "엔티티 그래프 이름 정의", attributeNodes = @NamedAttributeNode("fetch join 할 대상"))을 추가해준다.
@EntityGraph("Member.all")
List<Member> findEntityGraphByUsername(@Param("username") String username);그리고 MemberRepository에서 @EntityGraph("정의한 엔티티 그래프 이름") 형식으로 Member 객체에 선언한 @NamedEntityGraph를 사용한다.
정리
- 간단한 경우 : @EntityGraph 사용
- 복잡한 경우 : JPQL fetch join 사용
JPA Hint & Lock
JPA Hint
SQL 힌트가 아니라 JPA 구현체 에게 제공하는 힌트(JPA 쿼리 힌트)
ReadOnly 힌트
ReadOnly 힌트는 @QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))를 사용하여 적용한다.
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);readOnly = true이면 성능 최적화에서 스냅샷을 만들지 않는다.
@Test
public void queryHint() {
// given
Member member1 = memberRepository.save(new Member("member1", 10));
memberRepository.save(member1);
em.flush(); // 1차 캐시가 남음
em.clear(); // 영속성 컨텍스트를 날림
// when
Member findMember = memberRepository.findById(member1.getId()).get();
findMember.setUsername("member2");
em.flush(); // 변경 감지 체크를 함
}위와 같이 findById로 member1의 이름을 member2로 변경하고 em.flush()를 날리면 변경 감지로 인해 update 쿼리가 날라간다.
@Test
public void queryHint() {
// given
Member member1 = memberRepository.save(new Member("member1", 10));
memberRepository.save(member1);
em.flush(); // 1차 캐시가 남음
em.clear(); // 영속성 컨텍스트를 날림
// when
Member findMember = memberRepository.findReadOnlyByUsername("member1");
findMember.setUsername("member2");
em.flush(); // 변경 감지 체크를 안함
}
위와 같이 @QueryHint를 적용해 readOnly로 설정한 findReadOnlyByUsername()를 사용하여 member1을 조회한 뒤, member2로 이름을 변경하고 em.flush()를 했다. 그러면 변경을 했는지 비교할 대상인 스냅샷을 만들지 않아서 이름을 변경해도 update 쿼리가 날라가지 않는다.
즉, readOnly = true로 설정을 하면, 스냅샷을 만들지 않으므로 변경 감지 체크를 하지 않는다.(update 쿼리를 날리지 않음)
"나는 100% 조회용으로만 쓸거야!"라고 한다면 이걸 최적화 할 수 있는 방법은 있다. 하지만 이 방법을 하이버네이트는 제공하지만 JPA 표준은 제공하지 않는다. 따라서 하이버네이트에게 힌트를 줄 수 있게 한 것이 JPA Hint 이다.
성능 관련해서 readOnly = true를 처음부터 프로젝트 전체에 깔고가는 것은 추천하지 않는다.
전체 100% 중 성능을 떨어트리는 주요 요인인 복잡한 조회 쿼리 자체이기 때문에 readOnly를 깔고 간다고 해도 성능이 크게 나아지지는 않는다.
따라서 성능 테스트를 해보고, readOnly를 설정해야 해결이 될 것 같다 하면 그 때 설정하면 되고, 만약 readOnly로 해결하지 못할 것이라는 판단을 하면 캐시와 같은 다른 방법을 사용하는 것으로 결정하면 된다.
Lock (주제가 어려워서 소개만..)
Lock은 DB에서 select 할 때, 다른 곳에서 건들지 못하도록 락을 거는 것으로 JPA도 Lock을 지원한다.
org.springframeork.data.jpa.repository.Lock 어노테이션을 사용한다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
List<Member> findLockByUsername(String username);@Test
public void lock() {
// given
Member member1 = new Member("member1", 10);
memberRepository.save(member1);
em.flush();
em.clear();
// when
List<Member> result = memberRepository.findLockByUsername("member1");
}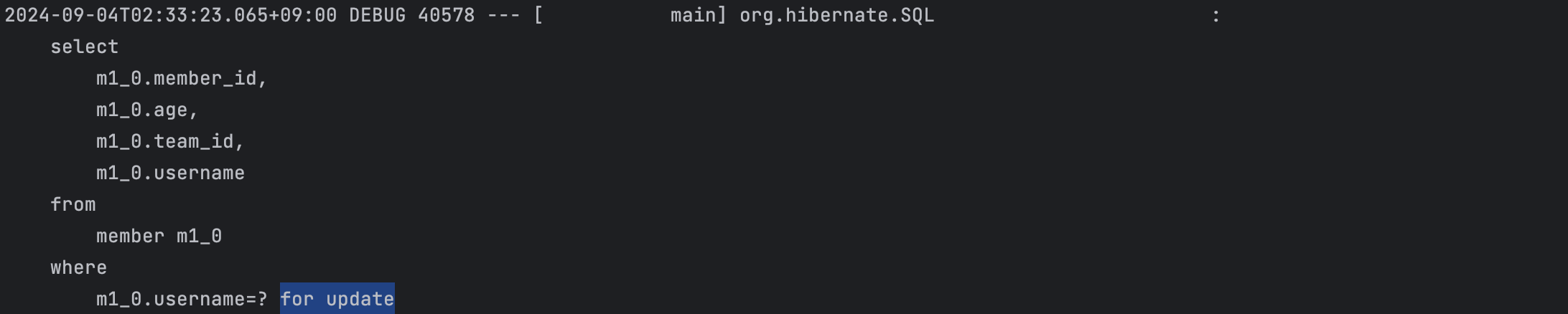
쿼리의 마지막에 for update가 붙은 것을 확인할 수 있다. 이는 DB 방언마다 동작 방식이 다르기 때문에 매뉴얼을 참고해야 한다.
Lock은 실시간 트래픽이 많은 서비스에서는 가급적 락을 걸면 안된다!!
[출처]
https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81-%EB%8D%B0%EC%9D%B4%ED%84%B0-JPA-%EC%8B%A4%EC%A0%84 → 이 글은 김영한님의 "실전! 스프링 데이터 JPA" 강의 중 5장을 듣고 정리한 내용입니다.