
이번에는 주문내역에서 추가로 주문한 상품 정보를 추가로 조회하는 부분에 대하여 진행한다.
앞에서는 XtoOne(OneToOne, ManyToOne) 관계만 있었지만 이번에는 컬렉션인 일대다 관계(OneToMany)를 조회하고, 최적화하는 방법에 대해 정리한다.
주문 조회
V1 : 엔티티를 직접 노출
@GetMapping("/api/v1/orders")
public List<Order> ordersV1() {
List<Order> all = orderRepository.findAllByString(new OrderSearch());
for (Order order : all) {
order.getMember().getName(); // 객체 LAZY 강제 초기화
order.getDelivery().getAddress(); // 객체 LAZY 강제 초기화
List<OrderItem> orderItems = order.getOrderItems();
orderItems.stream().forEach(o -> o.getItem().getName()); // Order 내의 Item도 LAZY 강제 초기화
}
return all;
}OrderItem, Item 관계를 직접 초기화하면서 Hibernate5JakartaModule 설정에 의해 엔티티를 JSON으로 생성한다. 양방향 연관관계라면 무한 루프에 걸리지 않도록 한쪽에 @JsonIgnore을 추가해줘야 한다.
엔티티를 직접 노출하기 때문에 좋은 방법이 아니다.
V2 : 엔티티를 DTO로 변환(fetch join 사용 X)
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return result;
}
@Getter
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems; // OrderItem 엔티티를 반환하면 안되고 Dto로 반환해야 한다!!!
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
//order.getOrderItems().stream().forEach(o -> o.getItem().getName());
//orderItems = order.getOrderItems(); // OrderItems 엔티티를 직접적으로 반환하면 안된다. -> Dto로 반환해야 됨
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
@Getter
static class OrderItemDto {
private String itemName; // 상품명
private int orderPrice; // 주문 가격
private int count; // 주문 수량
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
Order를 Dto로 반환하면 좌측의 사진처럼 OrderItem 엔티티가 그대로 반환된다(private List<OrderItem> orderItems;). 따라서 컬렉션 내부의 데이터인 OrderItem도 private List<OrderItemDto> orderItems;로 변환하여 반환해야 한다. 우측 그림처럼 내부까지 모두 Dto로 변환해서 반환하면 원하는 값들만 Dto에 추가하여 반환할 수 있다.
즉, 엔티티를 외부로 노출하지 말라는 것은 겉 뿐만 아니라 컬렉션 내부까지 해당된다.
하지만, 이 경우 지연 로딩으로 너무 많은 SQL이 실행된다.
order 1번 + member, address N번(order 조회수 만큼) + orderItem N번(order 조회수 만큼) + item N번(orderItem 조회수 만큼)
V3 : 엔티티를 DTO로 변환 - 페치 조인 최적화(fetch join 사용 O)
/** OrderApiController */
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllwithItem();
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return result;
}
/** OrderRepository */
public List<Order> findAllwithItem() { // Springboot3, Hibernate6 에서는 distinct를 추가하지 않아도 자동으로 중복제거가 되어 결과가 2개만 나온다.
return em.createQuery(
"SELECT distinct o FROM Order o " +
"JOIN FETCH o.member m " +
"JOIN FETCH o.delivery d " +
"JOIN FETCH o.orderItems oi " +
"JOIN FETCH oi.item i", Order.class)
//.setFirstResult(1)
//.setMaxResults(100) // 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징함 -> 매우 위험
.getResultList();
}V3에서는 페치 조인을 사용하여 SQL이 1번만 실행된다.
문제점 1 - 중복되는 데이터가 발생함
findAllwithItem()의 JOIN FETCH o.orderItems를 하면 order가 2개가 이닌 4개가 나오는 중복 출력이 발생한다. 따라서 JPQL에 distinct를 추가해야 한다(단, 필자는 SpringBoot3, Hibernate6 버전을 사용하여 distinct를 추가하지 않아도 중복이 제거됬다). distinct를 사용한 이유는 1대다 조인이 있으므로 데이터베이스는 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다. JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러주기에 order 가 컬렉션 페치 조인 때문에 중복 조회되는 것을 막아준다.
문제점 2 - 페이징 처리가 불가능
하지만 치명적인 단점으로는 컬렉션 페치 조인을 사용하면 페이징이 불가능하다.
페치 조인 시, distinct를 사용하여 중복된 데이터를 걸러낸다고 하더라도 실제 DB에서는 모든 값이 일치하지 않는 이상 데이터의 중복이 제거되지 않는다. 그래서 JPA는 어디서부터 조회를 해야되는지 판단을 못하게 되고, 이러한 문제를 해결하기 위해 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다(매우 위험함). 데이터가 많을 경우, OutOfMemory 에러가 발생할 수 있다.
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory즉, 일대다가 아니면 페치 조인을 사용해도 되지만, 일대다인 경우 페치 조인을 사용하면 페이징이 불가능하므로 결론적으로는 사용하면 안된다.
문제점3 - 여러 개의 컬렉션일 경우 페치 조인을 사용할 수 없다.
컬렉션이 둘 이상일 때, 패치 조인을 사용하게 되면, 데이터의 중복 제거가 애매해지고, 부정합한 데이터가 발생할 수 있기 때문에 이러한 경우에는 다른 방법을 사용해야 한다. (V3.1)
V3.1 : 엔티티를 DTO로 변환 - 페이징과 한계 돌파
/** OrderApiController */
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(
@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}
/** OrderRepository */
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o " +
"join fetch o.member m " +
"join fetch o.delivery d", Order.class
)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
/** application.yml */
spring:jpa:properties:hibernate:default_batch_fetch_size: 100페치 조인을 사용하게 되면 쿼리가 1번만 실행되지만, 컬렉션이 포함된 엔티티를 조회하는 경우, 1:N 관계로 인해 row가 N배로 증가하는 단점과 페이징이 안된다는 단점이 있었다.
위의 단점을 보완하기 위해 컬렉션 엔티티를 페치 조인에서 제외시키고, 글로벌 전략인 hibernate.default_batch_fetch_size를 설정했다.
그러면 페이징 하면서 컬렉션 엔티티를 함께 조회하는 방법은?
- 먼저 XToOne(OneToOne, ManyToOne) 관계를 모두 페치 조인 한다. ToOne 관계는 row 수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다.
- 컬렉션은 지연 로딩으로 조회한다.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size, @BatchSize를 적용한다.
- hibernate.default_batch_fetch_size : 글로벌 설정 (기본값으로 설정해주는게 좋음)
- 프록시 객체를 설정한 size만큼 IN 절을 사용하여 데이터를 미리 가져오는 방식이다.
- size의 크기는 DB마다 IN 절에서 사용하는 갯수에 제한이 있을 수 있으므로 1000을 넘게 사용하지 않는 것이 좋다.
- 100~1000 사이를 선택하는 것을 권장한다.
- @BatchSize : 개별 최적화(컬렉션은 컬렉션 필드에, 엔티티는 엔티티 클래스에 적용)
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
- hibernate.default_batch_fetch_size : 글로벌 설정 (기본값으로 설정해주는게 좋음)
장점
- 쿼리 호출 수가 1 + N -> 1 + 1 로 최적화 된다.
- member와 delivery를 페치 조인으로 한 번에 가져오고, orderItems와 item을 IN 쿼리로 한 번에 다 가져와서 총 1+1+1 번 쿼리가 실행된다. 즉, 이렇게 하면 페이징이 가능하고, 성능이 최적화 된다.
- 조인보다 DB 데이터 전송량이 최적화 된다. (Order와 OrderItem을 조인하면 Order가 OrderItem 만큼 중복해서 조회된다. 이 방법은 각각 조회하므로 전송해야할 중복 데이터가 없다.)
- 페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 전송량이 감소한다.
- 컬렉션 페치 조인은 페이징이 불가능 하지만 이 방법은 페이징이 가능하다.
결론
ToOne 관계는 페치 조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치 조인으로 쿼리 수를 줄이고, 나머지는 hibernate.default_batch_fetch_size로 최적화 하자.
V4 : JPA에서 DTO로 직접 조회
@GetMapping("/api/v4/orders")
public List<OrderQueryDto> ordersV4() {
return orderQueryRepository.findOrderQueryDtos();
}@Repository
@RequiredArgsConstructor
public class OrderQueryRepository {
/**
* 화면과 밀접한 것들은 쿼리랑 밀접한 것들이 많음. -> query 에 넣음
* 핵심 비즈니스 로직들을 참조하면서 진행 -> 관심사 분리
*/
private final EntityManager em;
public List<OrderQueryDto> findOrderQueryDtos() {
// 루트 조회(ToOne 코드를 모두 한 번에 조회)
List<OrderQueryDto> result = findOrders(); // query 1번 -> 1개
// 루프를 돌면서 컬렉션 추가(추가 쿼리 실행)
result.forEach(o -> { // 루프를 돌면서 직접 처리
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId()); // query 2번 -> N개
o.setOrderItems(orderItems);
});
return result;
}
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
"from OrderItem oi " +
"join oi.item i " +
"where oi.order.id = :orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getResultList();
}
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"SELECT new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address) " +
"FROM Order o " +
"JOIN o.member m " +
"JOIN o.delivery d", OrderQueryDto.class)
.getResultList();
}
}@Data
public class OrderItemQueryDto {
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}JPA에서 DTO를 직접 조회하는 경우에는 엔티티를 직접 조회하는 것이 아니기 때문에 별도의 패키지로 구성하는 것이 좋다. 따라서 repository/order/query/ 에 위 코드들을 위치시켰다.
- 이 경우 쿼리는 루트에서 1번, 컬렉션에서 N번이 실행되어 결론적으로는 N + 1 문제가 발생한다.
- ToOne(ManyToOne, OneToOne) 관계들을 먼저 조회하고, ToMany(OneToMany) 관계는 각각 별도로 처리한다.
- ToOne 관계는 조인해도 데이터 row 수가 증가하지 않는다.
- ToMany 관계는 조인하면 row 수가 증가한다.
- row 수가 증가하지 않는 ToOne 관계는 조인으로 최적화하기 쉬우므로 한 번에 조회하고, ToMany 관계는 최적화하기 어려우므로 findOrderItems() 같은 별도의 메서드로 조회한다.
V5 : JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
/** OrderApiController */
@GetMapping("/api/v5/orders")
public List<OrderQueryDto> ordersV5() {
return orderQueryRepository.findAllByDto_optimization();
}
/** OrderQueryRepository */
public List<OrderQueryDto> findAllByDto_optimization() {
// 루트 조회(toOne 코드를 모두 한 번에 조회)
List<OrderQueryDto> result = findOrders(); // 1
// 현재 주문서와 관련된 orderItems를 한번에 조회
Map<Long, List<OrderItemQueryDto>> orderItemMap = findOrderItemMap(toOrderIds(result)); // 2~4
// 루프를 돌면서 컬렉션 추가(추가 쿼리 실행 X)
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId()))); // 5
return result;
}
private Map<Long, List<OrderItemQueryDto>> findOrderItemMap(List<Long> orderIds) {
// 3
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
"from OrderItem oi " +
"join oi.item i " +
"where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
// 4
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId()));
return orderItemMap;
}
private static List<Long> toOrderIds(List<OrderQueryDto> result) {
List<Long> orderIds = result.stream() // 2
.map(o -> o.getOrderId()) // map으로 o(OrderQueryDto)를 orderId로 바꾸고,
.collect(Collectors.toList()); // 그 값들을 리스트로 반환
return orderIds;
}
- ToOne 관계들을 먼저 조회하고,
- 여기서 식별자 orderIds 뽑기
- ToMany 관계인 OrderItem을 한꺼번에 조회한다. 쿼리문에에서 oi.order.id = :orderId 대신에 IN을 사용하여 oi.order.id IN :orderIds을 적용한다.
- orderItems를 코드로 작성하기 쉽고 성능 최적화를 위해 Map 형태로 바꿔준다.
- forEach로 돌리면서 orderItems를 넣어준다. orderItemMap 안에서 탐색하는데 키 값은 orderId 이므로 o.getOrderId()로 가져온다.
앞의 V1 ~ V4 들은 루프를 돌리자마자 쿼리를 날렸는데 이 방법은 em.createQuery에서 1번 실행하고, 메모리에서 Map으로 모두 가져온 후 매칭시켜서 값들을 가져온다. 그래서 Query는 총 2번(findOrders() 1번 + em.createQuery() 1번) 나간다.
V6 : JPA에서 DTO로 직접 조회, 플랫 데이터 최적화
/** OrderApiController */
@GetMapping("/api/v6/orders")
public List<OrderFlatDto> ordersV6() {
return orderQueryRepository.findAllByDto_flat();
}
/** OrderQueryRepository */
public List<OrderFlatDto> findAllByDto_flat() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderFlatDto(o.id, m.name, o.orderDate, o.status, d.address, i.name, oi.orderPrice, oi.count) " +
"from Order o " +
"join o.member m " +
"join o.delivery d " +
"join o.orderItems oi " +
"join oi.item i", OrderFlatDto.class)
.getResultList();
}
@Data
public class OrderFlatDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private String itemName;
private int orderPrice;
private int count;
public OrderFlatDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
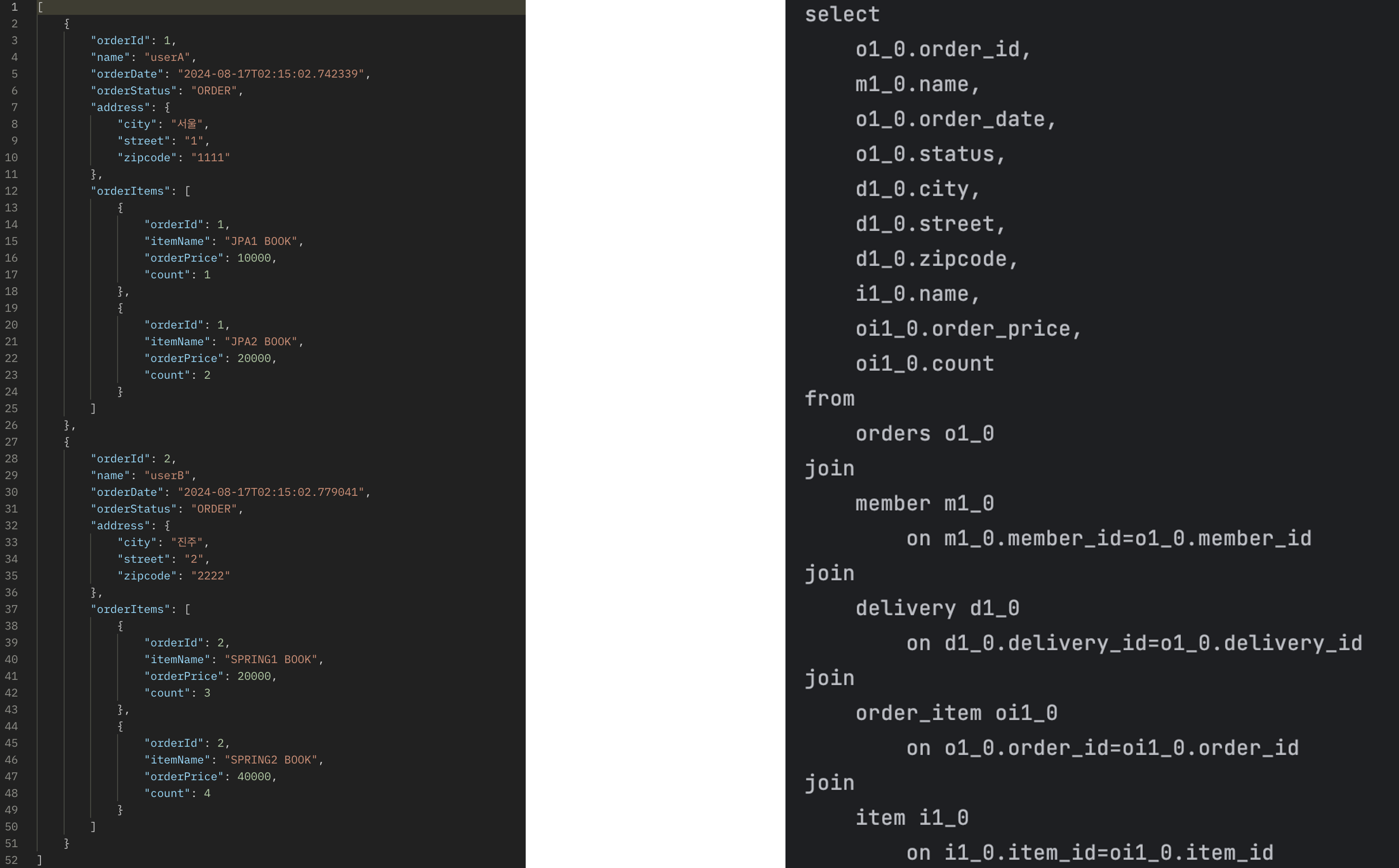
}위의 OrderApiController의 코드처럼 OrderFlatDto로 리스트를 조회하면 쿼리가 1번만 나가면서 아래와 같이 조회된다. 단, 문제점으로는 아래와 같이 orderItems를 조인하는 과정에서 oi 개수만큼 데이터가 뻥튀기된다.

일대다 조인을 했기 때문에 다 쪽 개수에 맞춰줘서 데이터가 중복되서 조회된다(JOIN의 속성으로 일 쪽이 다쪽에 개수를 맞추어서 중복으로 생성됨).
이와 같이 진행하면 단 한 번의 쿼리로 조회가 가능하지만, order를 기준으로 페이징이 불가능하다. 단, oi를 기준으로는 페이징이 가능하다.
이 때, 반환 타입을 OrderQueryDto로 맞추려면 OrderApiController의 List<OrderFlatDto>를 List<OrderQueryDto>로 수정해서 아래와 같이 수정한다.
/** OrderApiController */
@GetMapping("/api/v6/orders")
public List<OrderQueryDto> ordersV6() {
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(), o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(), o.getItemName(), o.getOrderPrice(), o.getCount()), toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(), e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(), e.getKey().getAddress(), e.getValue()))
.collect(toList());
}
@Data
@EqualsAndHashCode(of = "orderId")
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
// 중간 생략 //
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, List<OrderItemQueryDto> orderItems) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.orderItems = orderItems;
}
}
findAllByDto_flat() 메서드 부분에서 flats.stream() 부분은 OrderFlatDto를 OrderQueryDto 형태로 바꾸기 위해 추가한 부분인데 복잡하므로 넘어가겠다.
위에서 설명했다시피 일대다 조인이 있기 때문에 데이터가 중복되어 조회된다. 이를 컨트롤러에서 flats.stream()을 통해 중복을 걸러내서 OrderQueryDto에 알맞게 매칭하는 것이다. 중복을 구분하기 위해 OrderQueryDto에 @EqualsAndHashCode(of = "orderId") 애노테이션을 추가해줘야 한다.
V6의 장점으로는 쿼리를 한 번에 조회하는 것이다.
단점으로 쿼리는 한 번 이지만 조인으로 인해 DB에서 중복 데이터가 추가되므로 상황에 따라 V5보다 느릴 수 있다. 또한 애플리케이션에서 추가 작업이 크다(flats.stream() 부분과 같이 복잡함). 그리고 일대다 조인에서 '일' 단위로 페이징이 불가능하다(Order 단위로 페이징 불가).
정리
방식
- 엔티티 조회
- 엔티티를 조회해서 그대로 반환 : V1
- 엔티티 조회 후 DTO로 변환 : V2
- 페치 조인으로 쿼리 수 최적화 : V3
- 컬렉션 페이징과 한계 돌파 : V3.1
- 컬렉션은 페치 조인 시, 페이징 불가능
- ToOne 관계는 페치 조인으로 쿼리 수 최적화
- 컬렉션은 페치 조인 대신에 지연 로딩을 유지하고, hibernate.default_batch_fatch_size, @BatchSize로 최적화
- DTO 직접 조회
- JPA에서 DTO를 직접 조회 : V4
- 컬렉션 조회 최적화 - 일대다 관계인 컬렉션은 IN 절을 활용하여 메모리에 미리 조회해서 최적화 : V5
- 플랫 데이터 최적화 - JOIN 결과를 그대로 조회 후 애플리케이션에서 원하는 모양으로 직접 변환 : V6
- 엔티티 조회 방식 : 페치 조인이나, hibernate.default_batch_fatch_size, @BatchSize 같이 코드를 거의 수정하지 않고, 옵션만 약간 변경해서 성능 최적화를 시도할 수 있다.
- DTO 직접 조회 방식 : 성능을 최적화 하거나 성능 최적화 방식을 변경할 때 많은 코드를 변경해야 한다.
권장 순서
- 엔티티 조회 방식으로 우선 접근 (V2)
- 페치 조인으로 쿼리 수를 최적화(V3)
- 컬렉션 최적화
- 페이징 필요 O : hibernate.default_batch_fatch_size, @BatchSize로 최적화
- 페이징 필요 X : 페치 조인 사용
- 엔티티 조회 방식으로 해결이 안되면 DTO 조회 방식 사용
- DTO 조회 방식으로 해결이 안되면 NativeSQL or Spring JDBCTimplate 사용
개발자는 성능 최적화와 코드 복잡도 사이에서 줄타기를 해야 하는데 항상 그런 것은 아니지만 보통 성능 최적화는 단순한 코드를 복잡한 코드로 몰고 간다. 엔티티 조회 방식은 JPA가 많은 부분을 최적화해주기 때문에 단순한 코드를 유지하면서, 성능을 최적화할 수 있다. 반면에 DTO 조회 방식은 SQL을 직접 다루는 것과 유사하기 때문에, 둘 사이에 줄타기를 해야 한다.
DTO 조회 방식의 선택지 (V4, V5, V6)
- DTO로 조회하는 방법은 각각 장단이 있다. 단순하게 쿼리가 1번 실행된다고 V6가 항상 좋은 방법인 것은 아니다.
- V4는 코드가 단순하다. 특정 주문 한 건만 조회하면 이 방식을 사용해도 성능이 잘 나온다.(단건 조회)
- 조회한 Order 데이터가 1건이라면 OrderItem을 찾기 위한 쿼리도 1번만 실행하면 된다.
- V5는 코드가 복잡하다. 여러 주문을 한꺼번에 조회하는 경우에는 V4 대신에 이것을 최적화한 V5 방식을 사용해야 한다.
- 조회한 Order 데이터가 1000건인데, V4 방식을 그대로 사용하면, 쿼리가 총 1 + 1000번 실행된다. 여기서 1은 Order을 조회한 쿼리고, 1000은 조회된 Order의 row 수다. V5 방식으로 최적화하면 쿼리가 총 1 + 1번만 실행된다. 상황에 따라 다르겠지만 운영 환경에서 100배 이상의 성능 차이가 날 수 있다.
- V6는 완전히 다른 접근 방식이다. 쿼리 한 번으로 최적화가 되어서 상당히 좋아 보이지만, Order를 기준으로 페이징이 불가능하다. 실무에서는 수백이나 수천건 단위로 페이징 처리가 필요하므로 이 방법은 선택하기 어려운 방법이다. 그리고 데이터가 많으면 중복 전송이 증가해서 V5와 비교해서 성능 차이도 미비하다.
[출처]
https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81%EB%B6%80%ED%8A%B8-JPA-API%EA%B0%9C%EB%B0%9C-%EC%84%B1%EB%8A%A5%EC%B5%9C%EC%A0%81%ED%99%94 → 이 글은 김영한님의 JPA 활용 2편 강의 중 4장을 듣고 정리한 내용입니다.
https://lealea.tistory.com/131
'Spring > 자바 ORM 표준 JPA 프로그래밍' 카테고리의 다른 글
| [Spring Data JPA] 1. 공통 인터페이스 기능 (0) | 2024.08.24 |
|---|---|
| [JPA 활용 2] 4. OSIV와 성능 최적화 (0) | 2024.08.17 |
| [JPA 활용 2] 2. API 개발 고급 - 지연 로딩과 조회 성능 최적화 (0) | 2024.08.15 |
| [JPA 활용 2] 1. API 개발 기본 (0) | 2024.08.12 |
| [JPA 기본편] 11. 객체지향 쿼리 언어2 - 중급 문법 (0) | 2024.06.24 |
이번에는 주문내역에서 추가로 주문한 상품 정보를 추가로 조회하는 부분에 대하여 진행한다.
앞에서는 XtoOne(OneToOne, ManyToOne) 관계만 있었지만 이번에는 컬렉션인 일대다 관계(OneToMany)를 조회하고, 최적화하는 방법에 대해 정리한다.
주문 조회
V1 : 엔티티를 직접 노출
@GetMapping("/api/v1/orders")
public List<Order> ordersV1() {
List<Order> all = orderRepository.findAllByString(new OrderSearch());
for (Order order : all) {
order.getMember().getName(); // 객체 LAZY 강제 초기화
order.getDelivery().getAddress(); // 객체 LAZY 강제 초기화
List<OrderItem> orderItems = order.getOrderItems();
orderItems.stream().forEach(o -> o.getItem().getName()); // Order 내의 Item도 LAZY 강제 초기화
}
return all;
}OrderItem, Item 관계를 직접 초기화하면서 Hibernate5JakartaModule 설정에 의해 엔티티를 JSON으로 생성한다. 양방향 연관관계라면 무한 루프에 걸리지 않도록 한쪽에 @JsonIgnore을 추가해줘야 한다.
엔티티를 직접 노출하기 때문에 좋은 방법이 아니다.
V2 : 엔티티를 DTO로 변환(fetch join 사용 X)
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return result;
}
@Getter
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems; // OrderItem 엔티티를 반환하면 안되고 Dto로 반환해야 한다!!!
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
//order.getOrderItems().stream().forEach(o -> o.getItem().getName());
//orderItems = order.getOrderItems(); // OrderItems 엔티티를 직접적으로 반환하면 안된다. -> Dto로 반환해야 됨
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(Collectors.toList());
}
}
@Getter
static class OrderItemDto {
private String itemName; // 상품명
private int orderPrice; // 주문 가격
private int count; // 주문 수량
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}Order를 Dto로 반환하면 좌측의 사진처럼 OrderItem 엔티티가 그대로 반환된다(private List<OrderItem> orderItems;). 따라서 컬렉션 내부의 데이터인 OrderItem도 private List<OrderItemDto> orderItems;로 변환하여 반환해야 한다. 우측 그림처럼 내부까지 모두 Dto로 변환해서 반환하면 원하는 값들만 Dto에 추가하여 반환할 수 있다.
즉, 엔티티를 외부로 노출하지 말라는 것은 겉 뿐만 아니라 컬렉션 내부까지 해당된다.
하지만, 이 경우 지연 로딩으로 너무 많은 SQL이 실행된다.
order 1번 + member, address N번(order 조회수 만큼) + orderItem N번(order 조회수 만큼) + item N번(orderItem 조회수 만큼)
V3 : 엔티티를 DTO로 변환 - 페치 조인 최적화(fetch join 사용 O)
/** OrderApiController */
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllwithItem();
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return result;
}
/** OrderRepository */
public List<Order> findAllwithItem() { // Springboot3, Hibernate6 에서는 distinct를 추가하지 않아도 자동으로 중복제거가 되어 결과가 2개만 나온다.
return em.createQuery(
"SELECT distinct o FROM Order o " +
"JOIN FETCH o.member m " +
"JOIN FETCH o.delivery d " +
"JOIN FETCH o.orderItems oi " +
"JOIN FETCH oi.item i", Order.class)
//.setFirstResult(1)
//.setMaxResults(100) // 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징함 -> 매우 위험
.getResultList();
}V3에서는 페치 조인을 사용하여 SQL이 1번만 실행된다.
문제점 1 - 중복되는 데이터가 발생함
findAllwithItem()의 JOIN FETCH o.orderItems를 하면 order가 2개가 이닌 4개가 나오는 중복 출력이 발생한다. 따라서 JPQL에 distinct를 추가해야 한다(단, 필자는 SpringBoot3, Hibernate6 버전을 사용하여 distinct를 추가하지 않아도 중복이 제거됬다). distinct를 사용한 이유는 1대다 조인이 있으므로 데이터베이스는 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다. JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러주기에 order 가 컬렉션 페치 조인 때문에 중복 조회되는 것을 막아준다.
문제점 2 - 페이징 처리가 불가능
하지만 치명적인 단점으로는 컬렉션 페치 조인을 사용하면 페이징이 불가능하다.
페치 조인 시, distinct를 사용하여 중복된 데이터를 걸러낸다고 하더라도 실제 DB에서는 모든 값이 일치하지 않는 이상 데이터의 중복이 제거되지 않는다. 그래서 JPA는 어디서부터 조회를 해야되는지 판단을 못하게 되고, 이러한 문제를 해결하기 위해 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다(매우 위험함). 데이터가 많을 경우, OutOfMemory 에러가 발생할 수 있다.
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory즉, 일대다가 아니면 페치 조인을 사용해도 되지만, 일대다인 경우 페치 조인을 사용하면 페이징이 불가능하므로 결론적으로는 사용하면 안된다.
문제점3 - 여러 개의 컬렉션일 경우 페치 조인을 사용할 수 없다.
컬렉션이 둘 이상일 때, 패치 조인을 사용하게 되면, 데이터의 중복 제거가 애매해지고, 부정합한 데이터가 발생할 수 있기 때문에 이러한 경우에는 다른 방법을 사용해야 한다. (V3.1)
V3.1 : 엔티티를 DTO로 변환 - 페이징과 한계 돌파
/** OrderApiController */
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(
@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
List<OrderDto> result = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return result;
}
/** OrderRepository */
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o " +
"join fetch o.member m " +
"join fetch o.delivery d", Order.class
)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
/** application.yml */
spring:jpa:properties:hibernate:default_batch_fetch_size: 100페치 조인을 사용하게 되면 쿼리가 1번만 실행되지만, 컬렉션이 포함된 엔티티를 조회하는 경우, 1:N 관계로 인해 row가 N배로 증가하는 단점과 페이징이 안된다는 단점이 있었다.
위의 단점을 보완하기 위해 컬렉션 엔티티를 페치 조인에서 제외시키고, 글로벌 전략인 hibernate.default_batch_fetch_size를 설정했다.
그러면 페이징 하면서 컬렉션 엔티티를 함께 조회하는 방법은?
- 먼저 XToOne(OneToOne, ManyToOne) 관계를 모두 페치 조인 한다. ToOne 관계는 row 수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다.
- 컬렉션은 지연 로딩으로 조회한다.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size, @BatchSize를 적용한다.
- hibernate.default_batch_fetch_size : 글로벌 설정 (기본값으로 설정해주는게 좋음)
- 프록시 객체를 설정한 size만큼 IN 절을 사용하여 데이터를 미리 가져오는 방식이다.
- size의 크기는 DB마다 IN 절에서 사용하는 갯수에 제한이 있을 수 있으므로 1000을 넘게 사용하지 않는 것이 좋다.
- 100~1000 사이를 선택하는 것을 권장한다.
- @BatchSize : 개별 최적화(컬렉션은 컬렉션 필드에, 엔티티는 엔티티 클래스에 적용)
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
- hibernate.default_batch_fetch_size : 글로벌 설정 (기본값으로 설정해주는게 좋음)
장점
- 쿼리 호출 수가 1 + N -> 1 + 1 로 최적화 된다.
- member와 delivery를 페치 조인으로 한 번에 가져오고, orderItems와 item을 IN 쿼리로 한 번에 다 가져와서 총 1+1+1 번 쿼리가 실행된다. 즉, 이렇게 하면 페이징이 가능하고, 성능이 최적화 된다.
- 조인보다 DB 데이터 전송량이 최적화 된다. (Order와 OrderItem을 조인하면 Order가 OrderItem 만큼 중복해서 조회된다. 이 방법은 각각 조회하므로 전송해야할 중복 데이터가 없다.)
- 페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 전송량이 감소한다.
- 컬렉션 페치 조인은 페이징이 불가능 하지만 이 방법은 페이징이 가능하다.
결론
ToOne 관계는 페치 조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치 조인으로 쿼리 수를 줄이고, 나머지는 hibernate.default_batch_fetch_size로 최적화 하자.
V4 : JPA에서 DTO로 직접 조회
@GetMapping("/api/v4/orders")
public List<OrderQueryDto> ordersV4() {
return orderQueryRepository.findOrderQueryDtos();
}@Repository
@RequiredArgsConstructor
public class OrderQueryRepository {
/**
* 화면과 밀접한 것들은 쿼리랑 밀접한 것들이 많음. -> query 에 넣음
* 핵심 비즈니스 로직들을 참조하면서 진행 -> 관심사 분리
*/
private final EntityManager em;
public List<OrderQueryDto> findOrderQueryDtos() {
// 루트 조회(ToOne 코드를 모두 한 번에 조회)
List<OrderQueryDto> result = findOrders(); // query 1번 -> 1개
// 루프를 돌면서 컬렉션 추가(추가 쿼리 실행)
result.forEach(o -> { // 루프를 돌면서 직접 처리
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId()); // query 2번 -> N개
o.setOrderItems(orderItems);
});
return result;
}
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
"from OrderItem oi " +
"join oi.item i " +
"where oi.order.id = :orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getResultList();
}
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"SELECT new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address) " +
"FROM Order o " +
"JOIN o.member m " +
"JOIN o.delivery d", OrderQueryDto.class)
.getResultList();
}
}@Data
public class OrderItemQueryDto {
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}JPA에서 DTO를 직접 조회하는 경우에는 엔티티를 직접 조회하는 것이 아니기 때문에 별도의 패키지로 구성하는 것이 좋다. 따라서 repository/order/query/ 에 위 코드들을 위치시켰다.
- 이 경우 쿼리는 루트에서 1번, 컬렉션에서 N번이 실행되어 결론적으로는 N + 1 문제가 발생한다.
- ToOne(ManyToOne, OneToOne) 관계들을 먼저 조회하고, ToMany(OneToMany) 관계는 각각 별도로 처리한다.
- ToOne 관계는 조인해도 데이터 row 수가 증가하지 않는다.
- ToMany 관계는 조인하면 row 수가 증가한다.
- row 수가 증가하지 않는 ToOne 관계는 조인으로 최적화하기 쉬우므로 한 번에 조회하고, ToMany 관계는 최적화하기 어려우므로 findOrderItems() 같은 별도의 메서드로 조회한다.
V5 : JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
/** OrderApiController */
@GetMapping("/api/v5/orders")
public List<OrderQueryDto> ordersV5() {
return orderQueryRepository.findAllByDto_optimization();
}
/** OrderQueryRepository */
public List<OrderQueryDto> findAllByDto_optimization() {
// 루트 조회(toOne 코드를 모두 한 번에 조회)
List<OrderQueryDto> result = findOrders(); // 1
// 현재 주문서와 관련된 orderItems를 한번에 조회
Map<Long, List<OrderItemQueryDto>> orderItemMap = findOrderItemMap(toOrderIds(result)); // 2~4
// 루프를 돌면서 컬렉션 추가(추가 쿼리 실행 X)
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId()))); // 5
return result;
}
private Map<Long, List<OrderItemQueryDto>> findOrderItemMap(List<Long> orderIds) {
// 3
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
"from OrderItem oi " +
"join oi.item i " +
"where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
// 4
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId()));
return orderItemMap;
}
private static List<Long> toOrderIds(List<OrderQueryDto> result) {
List<Long> orderIds = result.stream() // 2
.map(o -> o.getOrderId()) // map으로 o(OrderQueryDto)를 orderId로 바꾸고,
.collect(Collectors.toList()); // 그 값들을 리스트로 반환
return orderIds;
}
- ToOne 관계들을 먼저 조회하고,
- 여기서 식별자 orderIds 뽑기
- ToMany 관계인 OrderItem을 한꺼번에 조회한다. 쿼리문에에서 oi.order.id = :orderId 대신에 IN을 사용하여 oi.order.id IN :orderIds을 적용한다.
- orderItems를 코드로 작성하기 쉽고 성능 최적화를 위해 Map 형태로 바꿔준다.
- forEach로 돌리면서 orderItems를 넣어준다. orderItemMap 안에서 탐색하는데 키 값은 orderId 이므로 o.getOrderId()로 가져온다.
앞의 V1 ~ V4 들은 루프를 돌리자마자 쿼리를 날렸는데 이 방법은 em.createQuery에서 1번 실행하고, 메모리에서 Map으로 모두 가져온 후 매칭시켜서 값들을 가져온다. 그래서 Query는 총 2번(findOrders() 1번 + em.createQuery() 1번) 나간다.
V6 : JPA에서 DTO로 직접 조회, 플랫 데이터 최적화
/** OrderApiController */
@GetMapping("/api/v6/orders")
public List<OrderFlatDto> ordersV6() {
return orderQueryRepository.findAllByDto_flat();
}
/** OrderQueryRepository */
public List<OrderFlatDto> findAllByDto_flat() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderFlatDto(o.id, m.name, o.orderDate, o.status, d.address, i.name, oi.orderPrice, oi.count) " +
"from Order o " +
"join o.member m " +
"join o.delivery d " +
"join o.orderItems oi " +
"join oi.item i", OrderFlatDto.class)
.getResultList();
}
@Data
public class OrderFlatDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private String itemName;
private int orderPrice;
private int count;
public OrderFlatDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}위의 OrderApiController의 코드처럼 OrderFlatDto로 리스트를 조회하면 쿼리가 1번만 나가면서 아래와 같이 조회된다. 단, 문제점으로는 아래와 같이 orderItems를 조인하는 과정에서 oi 개수만큼 데이터가 뻥튀기된다.
일대다 조인을 했기 때문에 다 쪽 개수에 맞춰줘서 데이터가 중복되서 조회된다(JOIN의 속성으로 일 쪽이 다쪽에 개수를 맞추어서 중복으로 생성됨).
이와 같이 진행하면 단 한 번의 쿼리로 조회가 가능하지만, order를 기준으로 페이징이 불가능하다. 단, oi를 기준으로는 페이징이 가능하다.
이 때, 반환 타입을 OrderQueryDto로 맞추려면 OrderApiController의 List<OrderFlatDto>를 List<OrderQueryDto>로 수정해서 아래와 같이 수정한다.
/** OrderApiController */
@GetMapping("/api/v6/orders")
public List<OrderQueryDto> ordersV6() {
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(), o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(), o.getItemName(), o.getOrderPrice(), o.getCount()), toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(), e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(), e.getKey().getAddress(), e.getValue()))
.collect(toList());
}
@Data
@EqualsAndHashCode(of = "orderId")
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
// 중간 생략 //
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, List<OrderItemQueryDto> orderItems) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.orderItems = orderItems;
}
}findAllByDto_flat() 메서드 부분에서 flats.stream() 부분은 OrderFlatDto를 OrderQueryDto 형태로 바꾸기 위해 추가한 부분인데 복잡하므로 넘어가겠다.
위에서 설명했다시피 일대다 조인이 있기 때문에 데이터가 중복되어 조회된다. 이를 컨트롤러에서 flats.stream()을 통해 중복을 걸러내서 OrderQueryDto에 알맞게 매칭하는 것이다. 중복을 구분하기 위해 OrderQueryDto에 @EqualsAndHashCode(of = "orderId") 애노테이션을 추가해줘야 한다.
V6의 장점으로는 쿼리를 한 번에 조회하는 것이다.
단점으로 쿼리는 한 번 이지만 조인으로 인해 DB에서 중복 데이터가 추가되므로 상황에 따라 V5보다 느릴 수 있다. 또한 애플리케이션에서 추가 작업이 크다(flats.stream() 부분과 같이 복잡함). 그리고 일대다 조인에서 '일' 단위로 페이징이 불가능하다(Order 단위로 페이징 불가).
정리
방식
- 엔티티 조회
- 엔티티를 조회해서 그대로 반환 : V1
- 엔티티 조회 후 DTO로 변환 : V2
- 페치 조인으로 쿼리 수 최적화 : V3
- 컬렉션 페이징과 한계 돌파 : V3.1
- 컬렉션은 페치 조인 시, 페이징 불가능
- ToOne 관계는 페치 조인으로 쿼리 수 최적화
- 컬렉션은 페치 조인 대신에 지연 로딩을 유지하고, hibernate.default_batch_fatch_size, @BatchSize로 최적화
- DTO 직접 조회
- JPA에서 DTO를 직접 조회 : V4
- 컬렉션 조회 최적화 - 일대다 관계인 컬렉션은 IN 절을 활용하여 메모리에 미리 조회해서 최적화 : V5
- 플랫 데이터 최적화 - JOIN 결과를 그대로 조회 후 애플리케이션에서 원하는 모양으로 직접 변환 : V6
- 엔티티 조회 방식 : 페치 조인이나, hibernate.default_batch_fatch_size, @BatchSize 같이 코드를 거의 수정하지 않고, 옵션만 약간 변경해서 성능 최적화를 시도할 수 있다.
- DTO 직접 조회 방식 : 성능을 최적화 하거나 성능 최적화 방식을 변경할 때 많은 코드를 변경해야 한다.
권장 순서
- 엔티티 조회 방식으로 우선 접근 (V2)
- 페치 조인으로 쿼리 수를 최적화(V3)
- 컬렉션 최적화
- 페이징 필요 O : hibernate.default_batch_fatch_size, @BatchSize로 최적화
- 페이징 필요 X : 페치 조인 사용
- 엔티티 조회 방식으로 해결이 안되면 DTO 조회 방식 사용
- DTO 조회 방식으로 해결이 안되면 NativeSQL or Spring JDBCTimplate 사용
개발자는 성능 최적화와 코드 복잡도 사이에서 줄타기를 해야 하는데 항상 그런 것은 아니지만 보통 성능 최적화는 단순한 코드를 복잡한 코드로 몰고 간다. 엔티티 조회 방식은 JPA가 많은 부분을 최적화해주기 때문에 단순한 코드를 유지하면서, 성능을 최적화할 수 있다. 반면에 DTO 조회 방식은 SQL을 직접 다루는 것과 유사하기 때문에, 둘 사이에 줄타기를 해야 한다.
DTO 조회 방식의 선택지 (V4, V5, V6)
- DTO로 조회하는 방법은 각각 장단이 있다. 단순하게 쿼리가 1번 실행된다고 V6가 항상 좋은 방법인 것은 아니다.
- V4는 코드가 단순하다. 특정 주문 한 건만 조회하면 이 방식을 사용해도 성능이 잘 나온다.(단건 조회)
- 조회한 Order 데이터가 1건이라면 OrderItem을 찾기 위한 쿼리도 1번만 실행하면 된다.
- V5는 코드가 복잡하다. 여러 주문을 한꺼번에 조회하는 경우에는 V4 대신에 이것을 최적화한 V5 방식을 사용해야 한다.
- 조회한 Order 데이터가 1000건인데, V4 방식을 그대로 사용하면, 쿼리가 총 1 + 1000번 실행된다. 여기서 1은 Order을 조회한 쿼리고, 1000은 조회된 Order의 row 수다. V5 방식으로 최적화하면 쿼리가 총 1 + 1번만 실행된다. 상황에 따라 다르겠지만 운영 환경에서 100배 이상의 성능 차이가 날 수 있다.
- V6는 완전히 다른 접근 방식이다. 쿼리 한 번으로 최적화가 되어서 상당히 좋아 보이지만, Order를 기준으로 페이징이 불가능하다. 실무에서는 수백이나 수천건 단위로 페이징 처리가 필요하므로 이 방법은 선택하기 어려운 방법이다. 그리고 데이터가 많으면 중복 전송이 증가해서 V5와 비교해서 성능 차이도 미비하다.
[출처]
https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81%EB%B6%80%ED%8A%B8-JPA-API%EA%B0%9C%EB%B0%9C-%EC%84%B1%EB%8A%A5%EC%B5%9C%EC%A0%81%ED%99%94 → 이 글은 김영한님의 JPA 활용 2편 강의 중 4장을 듣고 정리한 내용입니다.
https://lealea.tistory.com/131
'Spring > 자바 ORM 표준 JPA 프로그래밍' 카테고리의 다른 글
| [Spring Data JPA] 1. 공통 인터페이스 기능 (0) | 2024.08.24 |
|---|---|
| [JPA 활용 2] 4. OSIV와 성능 최적화 (0) | 2024.08.17 |
| [JPA 활용 2] 2. API 개발 고급 - 지연 로딩과 조회 성능 최적화 (0) | 2024.08.15 |
| [JPA 활용 2] 1. API 개발 기본 (0) | 2024.08.12 |
| [JPA 기본편] 11. 객체지향 쿼리 언어2 - 중급 문법 (0) | 2024.06.24 |